
statistics --- Hàm thống kê toán học¶
Added in version 3.4.
Source code: Lib/statistics.py
Mô-đun này cung cấp các chức năng tính toán thống kê toán học của dữ liệu số (có giá trị Real).
Mô-đun này không nhằm mục đích cạnh tranh với các thư viện của bên thứ ba như NumPy, SciPy hoặc các gói thống kê đầy đủ tính năng độc quyền nhằm vào các nhà thống kê chuyên nghiệp như Minitab, SAS và Matlab. Nó nhằm vào trình độ vẽ đồ thị và máy tính khoa học.
Trừ khi được ghi chú rõ ràng, các chức năng này hỗ trợ int, float, Decimal và Fraction. Hành vi với các loại khác (dù ở trong tháp số hay không) hiện không được hỗ trợ. Các bộ sưu tập có sự kết hợp của nhiều loại cũng không được xác định và phụ thuộc vào việc triển khai. Nếu dữ liệu đầu vào của bạn bao gồm nhiều loại hỗn hợp, bạn có thể sử dụng map() để đảm bảo kết quả nhất quán, ví dụ: map(float, input_data).
Một số bộ dữ liệu sử dụng giá trị NaN (không phải số) để biểu thị dữ liệu bị thiếu. Vì NaN có ngữ nghĩa so sánh bất thường nên chúng gây ra các hành vi đáng ngạc nhiên hoặc không xác định trong các hàm thống kê sắp xếp dữ liệu hoặc đếm số lần xuất hiện. Các chức năng bị ảnh hưởng là median(), median_low(), median_high(), median_grouped(), mode(), multimode() và quantiles(). Cần loại bỏ các giá trị NaN trước khi gọi các hàm này
>>> từ số liệu thống kê nhập trung bình
>>> từ nhập toán isnan
>>> từ itertools nhập filterfalse
>>> data = [20.7, float('NaN'),19.2, 18.3, float('NaN'), 14.4]
>>> được sắp xếp (dữ liệu) # This có hành vi đáng ngạc nhiên
[20.7, nan, 14.4, 18.3, 19.2, nan]
>>> kết quả trung vị (dữ liệu) # This là bất ngờ
16:35
>>> sum(map(isnan, data)) # Number của các giá trị bị thiếu
2
>>> clean = list(filterfalse(isnan, data)) # Strip Giá trị NaN
>>> sạch sẽ
[20,7, 19,2, 18,3, 14,4]
>>> đã sắp xếp (sạch) # Sorting hiện hoạt động như mong đợi
[14.4, 18.3, 19.2, 20.7]
>>> Kết quả trung bình (sạch) # This hiện đã được xác định rõ
18:75
Trung bình và thước đo của vị trí trung tâm¶
Các hàm này tính toán giá trị trung bình hoặc điển hình từ một tập hợp hoặc mẫu.
Giá trị trung bình số học ("trung bình") của dữ liệu. |
|
Trung bình số học dấu phẩy động nhanh, có trọng số tùy chọn. |
|
Ý nghĩa hình học của dữ liệu. |
|
Ý nghĩa hài hòa của dữ liệu. |
|
Ước tính phân bố mật độ xác suất của dữ liệu. |
|
Lấy mẫu ngẫu nhiên từ PDF được tạo bởi kde(). |
|
Median (giá trị trung bình) của dữ liệu. |
|
Dữ liệu trung bình thấp. |
|
Dữ liệu trung bình cao. |
|
Trung vị (phân vị thứ 50) của dữ liệu được nhóm. |
|
Chế độ đơn (giá trị phổ biến nhất) của dữ liệu rời rạc hoặc danh nghĩa. |
|
Danh sách các chế độ (giá trị phổ biến nhất) của dữ liệu rời rạc hoặc danh nghĩa. |
|
Chia dữ liệu thành các khoảng có xác suất bằng nhau. |
Các biện pháp lây lan¶
Các hàm này tính toán thước đo xem tổng thể hoặc mẫu có xu hướng sai lệch so với các giá trị điển hình hoặc trung bình bao nhiêu.
Độ lệch chuẩn dân số của dữ liệu. |
|
Phương sai dân số của dữ liệu. |
|
Độ lệch chuẩn mẫu của dữ liệu. |
|
Phương sai mẫu của dữ liệu. |
Thống kê mối quan hệ giữa hai đầu vào¶
Các hàm này tính toán số liệu thống kê liên quan đến mối quan hệ giữa hai đầu vào.
Hiệp phương sai mẫu cho hai biến. |
|
Hệ số tương quan Pearson và Spearman. |
|
Độ dốc và giao điểm cho hồi quy tuyến tính đơn giản. |
Chi tiết chức năng¶
Lưu ý: Các hàm không yêu cầu sắp xếp dữ liệu được cung cấp cho chúng. Tuy nhiên, để thuận tiện cho việc đọc, hầu hết các ví dụ đều hiển thị các chuỗi được sắp xếp.
- statistics.mean(data)¶
Trả về giá trị trung bình số học mẫu của data có thể là một chuỗi hoặc có thể lặp lại.
Giá trị trung bình số học là tổng của dữ liệu chia cho số điểm dữ liệu. Nó thường được gọi là "trung bình", mặc dù nó chỉ là một trong nhiều trung bình toán học khác nhau. Nó là thước đo vị trí trung tâm của dữ liệu.
Nếu data trống,
StatisticsErrorsẽ được nâng lên.Một số ví dụ về sử dụng:
>>> trung bình([1, 2, 3, 4, 4]) 2,8 >>> trung bình([-1.0, 2.5, 3.25, 5.75]) 2,625 >>> từ phân số nhập Phân số dưới dạng F >>> trung bình([F(3, 7), F(1, 21), F(5, 3), F(1, 3)]) Phân số(13, 21) >>> từ nhập thập phân Thập phân dưới dạng D >>> trung bình([D("0.5"), D("0.75"), D("0.625"), D("0.375")]) Thập phân('0.5625')
Ghi chú
Giá trị trung bình bị ảnh hưởng mạnh mẽ bởi outliers và không nhất thiết phải là ví dụ điển hình của các điểm dữ liệu. Để có thước đo central tendency mạnh mẽ hơn, mặc dù kém hiệu quả hơn, hãy xem
median().Giá trị trung bình mẫu đưa ra ước tính không thiên vị về giá trị trung bình thực của tổng thể, do đó khi lấy trung bình trên tất cả các mẫu có thể,
mean(sample)sẽ hội tụ về giá trị trung bình thực của toàn bộ tổng thể. Nếu data đại diện cho toàn bộ tổng thể chứ không phải một mẫu thìmean(data)tương đương với việc tính trung bình thực của tổng thể μ.
- statistics.fmean(data, weights=None)¶
Chuyển đổi data thành số float và tính giá trị trung bình số học.
Hàm này chạy nhanh hơn hàm
mean()và luôn trả vềfloat. Zz003zz có thể là một chuỗi hoặc có thể lặp lại. Nếu tập dữ liệu đầu vào trống, hãy tăngStatisticsError.>>> fmean([3.5, 4.0, 5.25]) 4,25
Trọng số tùy chọn được hỗ trợ. Ví dụ: một giáo sư chấm điểm cho một khóa học bằng cách chấm điểm các câu hỏi ở mức 20%, bài tập về nhà là 20%, bài kiểm tra giữa kỳ là 30% và bài kiểm tra cuối kỳ là 30%:
>>> điểm = [85, 92, 83, 91] >>> trọng số = [0,20, 0,20, 0,30, 0,30] >>> fmean(điểm, trọng lượng) 87,6
Nếu weights được cung cấp, nó phải có cùng độ dài với data nếu không
ValueErrorsẽ được nâng lên.Added in version 3.8.
Thay đổi trong phiên bản 3.11: Đã thêm hỗ trợ cho weights.
- statistics.geometric_mean(data)¶
Chuyển đổi data thành số float và tính giá trị trung bình hình học.
Giá trị trung bình hình học biểu thị xu hướng trung tâm hoặc giá trị điển hình của data bằng cách sử dụng tích của các giá trị (ngược lại với giá trị trung bình số học sử dụng tổng của chúng).
Tăng
StatisticsErrornếu tập dữ liệu đầu vào trống, nếu nó chứa số 0 hoặc nếu nó chứa giá trị âm. Zz001zz có thể là một chuỗi hoặc có thể lặp lại.Không có nỗ lực đặc biệt nào được thực hiện để đạt được kết quả chính xác. (Tuy nhiên, điều này có thể thay đổi trong tương lai.)
>>> round(geometric_mean([54, 24, 36]), 1) 36,0
Added in version 3.8.
- statistics.harmonic_mean(data, weights=None)¶
Trả về giá trị trung bình điều hòa của data, một chuỗi hoặc số có thể lặp lại của các số có giá trị thực. Nếu weights bị bỏ qua hoặc
Nonethì giả sử trọng số bằng nhau.Giá trị trung bình điều hòa là nghịch đảo của
mean()số học của các nghịch đảo của dữ liệu. Ví dụ: trung bình điều hòa của ba giá trị a, b và c sẽ tương đương với3/(1/a + 1/b + 1/c). Nếu một trong các giá trị bằng 0 thì kết quả sẽ bằng 0.Giá trị trung bình hài hòa là một loại giá trị trung bình, thước đo vị trí trung tâm của dữ liệu. Nó thường thích hợp khi tính trung bình các tỷ số hoặc tốc độ, ví dụ như tốc độ.
Giả sử một ô tô đi 10 km với tốc độ 40 km/h, sau đó đi thêm 10 km nữa với tốc độ 60 km/h. Tốc độ trung bình là gì?
>>> harmonic_mean([40, 60]) 48,0
Giả sử một ô tô đi với vận tốc 40 km/h trong 5 km và khi đường thông thoáng, tăng tốc lên 60 km/h trong 30 km còn lại của hành trình. Tốc độ trung bình là gì?
>>> harmonic_mean([40, 60],weights=[5, 30]) 56,0
StatisticsErrorđược tăng lên nếu data trống, bất kỳ phần tử nào nhỏ hơn 0 hoặc nếu tổng có trọng số không dương.Thuật toán hiện tại bị loại sớm khi gặp số 0 ở đầu vào. Điều này có nghĩa là các đầu vào tiếp theo không được kiểm tra tính hợp lệ. (Hành vi này có thể thay đổi trong tương lai.)
Added in version 3.6.
Thay đổi trong phiên bản 3.10: Đã thêm hỗ trợ cho weights.
- statistics.kde(data, h, kernel='normal', *, cumulative=False)¶
Kernel Density Estimation (KDE): Tạo hàm mật độ xác suất liên tục hoặc hàm phân phối tích lũy từ các mẫu rời rạc.
Ý tưởng cơ bản là làm mịn dữ liệu bằng a kernel function. để giúp rút ra những suy luận về một quần thể từ một mẫu.
Mức độ làm mịn được kiểm soát bởi tham số tỷ lệ h được gọi là băng thông. Các giá trị nhỏ hơn nhấn mạnh các đặc điểm cục bộ trong khi các giá trị lớn hơn cho kết quả mượt mà hơn.
Zz000zz xác định trọng số tương đối của các điểm dữ liệu mẫu. Nói chung, việc lựa chọn hình dạng hạt nhân không quan trọng bằng tham số làm mịn băng thông có ảnh hưởng nhiều hơn.
Các hạt nhân mang lại một số trọng số cho mỗi điểm mẫu bao gồm normal (gauss), logistic và sigmoid.
Các hạt nhân chỉ tính trọng số cho các điểm mẫu trong băng thông bao gồm rectangular (uniform), triangular, parabolic (epanechnikov), quartic (biweight), triweight và cosine.
Nếu cumulative đúng, sẽ trả về hàm phân phối tích lũy.
Một
StatisticsErrorsẽ được tăng lên nếu chuỗi data trống.Wikipedia has an example trong đó chúng ta có thể sử dụng
kde()để tạo và vẽ đồ thị hàm mật độ xác suất được ước tính từ một mẫu nhỏ:>>> mẫu = [-2.1, -1.3, -0.4, 1.9, 5.1, 6.2] >>> f_hat = kde(mẫu, h=1.5) >>> xarr = [i/100 cho i trong phạm vi(-750, 1100)] >>> yarr = [f_hat(x) cho x trong xarr]
Các điểm trong
xarrvàyarrcó thể được sử dụng để tạo biểu đồ PDF: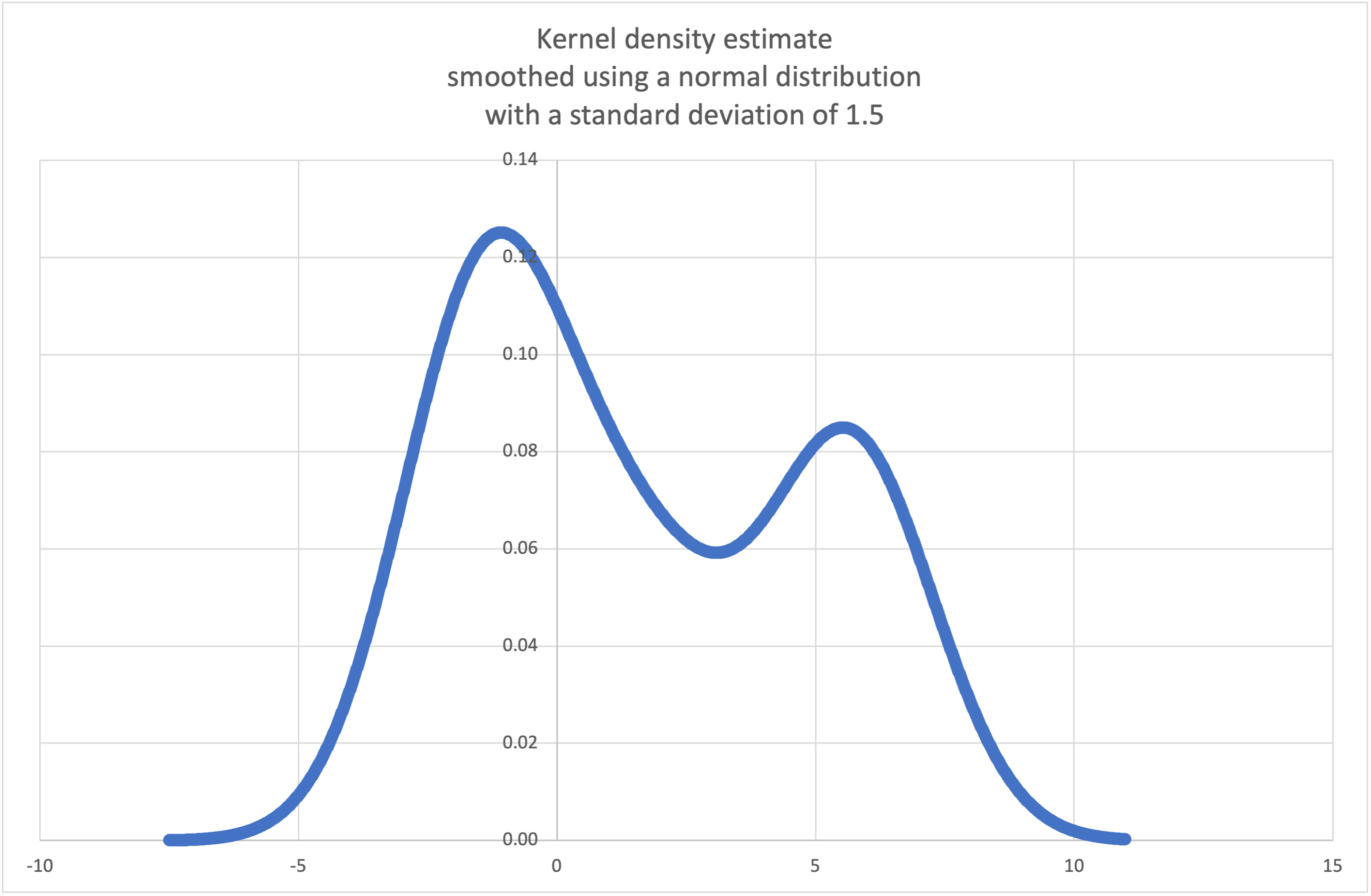
Added in version 3.13.
- statistics.kde_random(data, h, kernel='normal', *, seed=None)¶
Trả về hàm thực hiện lựa chọn ngẫu nhiên từ hàm mật độ xác suất ước tính do
kde(data, h, kernel)tạo ra.Việc cung cấp seed cho phép các lựa chọn có thể lặp lại. Trong tương lai, các giá trị có thể thay đổi một chút khi ước tính CDF nghịch đảo hạt nhân chính xác hơn được triển khai. Hạt giống có thể là số nguyên, float, str hoặc byte.
Một
StatisticsErrorsẽ được tăng lên nếu chuỗi data trống.Tiếp tục ví dụ về
kde(), chúng ta có thể sử dụngkde_random()để tạo các lựa chọn ngẫu nhiên mới từ hàm mật độ xác suất ước tính:>>> data = [-2.1, -1.3, -0.4, 1.9, 5.1, 6.2] >>> rand = kde_random(data, h=1.5, seed=8675309) >>> new_selections = [rand() for i in range(10)] >>> [round(x, 1) for x in new_selections] [0.7, 6.2, 1.2, 6.9, 7.0, 1.8, 2.5, -0.5, -1.8, 5.6]
Added in version 3.13.
- statistics.median(data)¶
Trả về giá trị trung bình (giá trị giữa) của dữ liệu số, sử dụng phương pháp "trung bình của hai phần giữa" phổ biến. Nếu data trống,
StatisticsErrorsẽ được nâng lên. data có thể là một chuỗi hoặc có thể lặp lại.Giá trị trung vị là thước đo mạnh mẽ về vị trí trung tâm và ít bị ảnh hưởng bởi sự hiện diện của các giá trị ngoại lệ. Khi số điểm dữ liệu là số lẻ thì trả về điểm dữ liệu ở giữa:
>>> trung vị([1, 3, 5]) 3
Khi số điểm dữ liệu là số chẵn thì trung vị được nội suy bằng cách lấy trung bình cộng của hai giá trị ở giữa:
>>> trung vị([1, 3, 5, 7]) 4.0
Điều này phù hợp khi dữ liệu của bạn rời rạc và bạn không bận tâm rằng trung vị có thể không phải là điểm dữ liệu thực tế.
Nếu dữ liệu là thứ tự (hỗ trợ các thao tác đặt hàng) nhưng không phải là số (không hỗ trợ phép cộng), hãy cân nhắc sử dụng
median_low()hoặcmedian_high()thay thế.
- statistics.median_low(data)¶
Trả về giá trị trung bình thấp của dữ liệu số. Nếu data trống,
StatisticsErrorsẽ được nâng lên. data có thể là một chuỗi hoặc có thể lặp lại.Trung vị thấp luôn là thành viên của tập dữ liệu. Khi số điểm dữ liệu là số lẻ, giá trị ở giữa sẽ được trả về. Khi nó chẵn, giá trị nhỏ hơn trong hai giá trị ở giữa sẽ được trả về.
>>> trung vị_thấp([1, 3, 5]) 3 >>> trung vị_thấp([1, 3, 5, 7]) 3
Sử dụng trung vị thấp khi dữ liệu của bạn rời rạc và bạn thích trung vị là điểm dữ liệu thực tế hơn là nội suy.
- statistics.median_high(data)¶
Trả về giá trị trung bình cao của dữ liệu. Nếu data trống,
StatisticsErrorsẽ được nâng lên. data có thể là một chuỗi hoặc có thể lặp lại.Trung vị cao luôn là thành viên của tập dữ liệu. Khi số điểm dữ liệu là số lẻ, giá trị ở giữa sẽ được trả về. Khi nó chẵn, giá trị lớn hơn trong hai giá trị ở giữa sẽ được trả về.
>>> trung vị_cao([1, 3, 5]) 3 >>> trung vị_cao([1, 3, 5, 7]) 5
Sử dụng trung vị cao khi dữ liệu của bạn rời rạc và bạn thích trung vị là điểm dữ liệu thực tế hơn là nội suy.
- statistics.median_grouped(data, interval=1.0)¶
Ước tính giá trị trung bình cho dữ liệu số có giá trị grouped or binned xung quanh điểm giữa của các khoảng có chiều rộng cố định liên tiếp.
Zz000zz có thể là bất kỳ dữ liệu số nào có thể lặp lại với mỗi giá trị chính xác là điểm giữa của một thùng. Ít nhất một giá trị phải có mặt.
Zz000zz là chiều rộng của mỗi thùng.
Ví dụ: thông tin nhân khẩu học có thể được tóm tắt thành các nhóm tuổi mười tuổi liên tiếp với mỗi nhóm được biểu thị bằng điểm giữa 5 năm của các khoảng:
>>> từ bộ đếm nhập bộ sưu tập >>> nhân khẩu học = Bộ đếm({ ... 25: 172, # 20 bước sang tuổi 30 ... 35: 484, # 30 đến 40 tuổi ... 45: 387, # 40 đến 50 tuổi ... 55: 22, # 50 đến 60 tuổi ... 65:6, # 60 tròn 70 tuổi ... }) ...
Phân vị thứ 50 (trung vị) là người thứ 536 trong số 1071 thành viên. Người đó nằm trong độ tuổi từ 30 đến 40.
Hàm
median()thông thường sẽ giả định rằng mọi người trong nhóm tuổi ba trăm tuổi chính xác là 35 tuổi. Một giả định hợp lý hơn là 484 thành viên của nhóm tuổi đó được phân bổ đều từ 30 đến 40. Để làm được điều đó, chúng tôi sử dụngmedian_grouped():>>> data = list(demographics.elements()) >>> trung vị(dữ liệu) 35 >>> round(median_grouped(data, interval=10), 1) 37,5
Người gọi có trách nhiệm đảm bảo các điểm dữ liệu được phân tách bằng bội số chính xác của interval. Điều này là cần thiết để có được kết quả chính xác. Hàm không kiểm tra điều kiện tiên quyết này.
Đầu vào có thể là bất kỳ loại số nào có thể bị ép buộc thành số float trong bước nội suy.
- statistics.mode(data)¶
Trả về điểm dữ liệu phổ biến nhất từ data rời rạc hoặc danh nghĩa. Chế độ (khi nó tồn tại) là giá trị tiêu biểu nhất và đóng vai trò là thước đo vị trí trung tâm.
Nếu có nhiều chế độ có cùng tần số, hãy trả về chế độ đầu tiên gặp phải trong data. Thay vào đó, nếu muốn có giá trị nhỏ nhất hoặc lớn nhất trong số đó, hãy sử dụng
min(multimode(data))hoặcmax(multimode(data)). Nếu đầu vào data trống,StatisticsErrorsẽ được nâng lên.modegiả định dữ liệu rời rạc và trả về một giá trị duy nhất. Đây là cách điều trị tiêu chuẩn của chế độ thường được dạy trong trường học:>>> chế độ([1, 1, 2, 3, 3, 3, 3, 4]) 3
Chế độ này độc đáo ở chỗ nó là thống kê duy nhất trong gói này cũng áp dụng cho dữ liệu danh nghĩa (không phải số):
>>> mode(["red", "blue", "blue", "red", "green", "red", "red"]) 'đỏ'
Chỉ hỗ trợ đầu vào có thể băm. Để xử lý loại
set, hãy cân nhắc chuyển sangfrozenset. Để xử lý loạilist, hãy cân nhắc chuyển sangtuple. Đối với các đầu vào hỗn hợp hoặc lồng nhau, hãy cân nhắc sử dụng thuật toán bậc hai chậm hơn này, chỉ phụ thuộc vào các kiểm tra đẳng thức:max(data, key=data.count).Thay đổi trong phiên bản 3.8: Bây giờ xử lý các tập dữ liệu đa phương thức bằng cách trả về chế độ đầu tiên gặp phải. Trước đây, nó báo lỗi
StatisticsErrorkhi tìm thấy nhiều hơn một chế độ.
- statistics.multimode(data)¶
Trả về danh sách các giá trị xuất hiện thường xuyên nhất theo thứ tự chúng xuất hiện lần đầu trong data. Sẽ trả về nhiều kết quả nếu có nhiều chế độ hoặc danh sách trống nếu data trống:
>>> đa chế độ('aabbbbccddddeeffffgg') ['b', 'd', 'f'] >>> đa chế độ('') []
Added in version 3.8.
- statistics.pstdev(data, mu=None)¶
Trả về độ lệch chuẩn của tổng thể (căn bậc hai của phương sai tổng thể). Xem
pvariance()để biết các đối số và các chi tiết khác.>>> pstdev([1.5, 2.5, 2.5, 2.75, 3.25, 4.75]) 0.986893273527251
- statistics.pvariance(data, mu=None)¶
Trả về phương sai tổng thể của data, một chuỗi không trống hoặc có thể lặp lại các số có giá trị thực. Phương sai, hay thời điểm thứ hai về giá trị trung bình, là thước đo độ biến thiên (sự lan truyền hoặc phân tán) của dữ liệu. Sự khác biệt lớn cho thấy dữ liệu bị dàn trải; một phương sai nhỏ cho thấy nó được tập hợp chặt chẽ xung quanh giá trị trung bình.
Nếu đối số thứ hai tùy chọn mu được đưa ra thì đó sẽ là giá trị trung bình population của data. Nó cũng có thể được sử dụng để tính mô men thứ hai xung quanh một điểm không phải là giá trị trung bình. Nếu thiếu hoặc
None(mặc định), giá trị trung bình số học sẽ được tính toán tự động.Sử dụng hàm này để tính phương sai từ toàn bộ tổng thể. Để ước tính phương sai từ một mẫu, hàm
variance()thường là lựa chọn tốt hơn.Tăng
StatisticsErrornếu data trống.Ví dụ:
>>> dữ liệu = [0,0, 0,25, 0,25, 1,25, 1,5, 1,75, 2,75, 3,25] >>> pvariance (dữ liệu) 1,25
Nếu bạn đã tính giá trị trung bình của dữ liệu, bạn có thể chuyển nó dưới dạng đối số thứ hai tùy chọn mu để tránh tính toán lại:
>>> mu = trung bình(dữ liệu) >>> pvariance(data, mu) 1,25
Số thập phân và phân số được hỗ trợ:
>>> từ nhập thập phân Thập phân dưới dạng D >>> pvariance([D("27.5"), D("30.25"), D("30.25"), D("34.5"), D("41.75")]) Thập phân('24.815') >>> từ phân số nhập Phân số dưới dạng F >>> pvariance([F(1, 4), F(5, 4), F(1, 2)]) Phân số(13, 72)
Ghi chú
Khi được gọi với toàn bộ tổng thể, kết quả này mang lại phương sai tổng thể σ². Thay vào đó, khi được gọi trên một mẫu, đây là phương sai mẫu sai lệch s², còn được gọi là phương sai với N bậc tự do.
Nếu bằng cách nào đó bạn biết được trung bình thực của tổng thể μ, thì bạn có thể sử dụng hàm này để tính phương sai của một mẫu, lấy trung bình tổng thể đã biết làm đối số thứ hai. Với điều kiện các điểm dữ liệu là một mẫu ngẫu nhiên của tổng thể, kết quả sẽ là ước tính không thiên vị về phương sai của tổng thể.
- statistics.stdev(data, xbar=None)¶
Trả về độ lệch chuẩn mẫu (căn bậc hai của phương sai mẫu). Xem
variance()để biết các đối số và các chi tiết khác.>>> stdev([1.5, 2.5, 2.5, 2.75, 3.25, 4.75]) 1.0810874155219827
- statistics.variance(data, xbar=None)¶
Trả về phương sai mẫu của data, một số có thể lặp lại của ít nhất hai số có giá trị thực. Phương sai, hay thời điểm thứ hai về giá trị trung bình, là thước đo độ biến thiên (sự lan truyền hoặc phân tán) của dữ liệu. Sự khác biệt lớn cho thấy dữ liệu bị dàn trải; một phương sai nhỏ cho thấy nó được tập hợp chặt chẽ xung quanh giá trị trung bình.
Nếu đối số thứ hai tùy chọn xbar được đưa ra thì đó sẽ là giá trị trung bình sample của data. Nếu thiếu hoặc
None(mặc định), giá trị trung bình sẽ được tính toán tự động.Sử dụng hàm này khi dữ liệu của bạn là mẫu từ một tập hợp. Để tính toán phương sai từ toàn bộ tập hợp, xem
pvariance().Tăng
StatisticsErrornếu data có ít hơn hai giá trị.Ví dụ:
>>> dữ liệu = [2,75, 1,75, 1,25, 0,25, 0,5, 1,25, 3,5] >>> phương sai (dữ liệu) 1.3720238095238095
Nếu bạn đã tính giá trị trung bình mẫu của dữ liệu, bạn có thể chuyển nó dưới dạng đối số thứ hai tùy chọn xbar để tránh tính toán lại:
>>> m = trung bình(dữ liệu) >>> phương sai(dữ liệu, m) 1.3720238095238095
Hàm này không cố gắng xác minh rằng bạn đã vượt qua giá trị trung bình thực tế là xbar. Việc sử dụng các giá trị tùy ý cho xbar có thể dẫn đến kết quả không hợp lệ hoặc không thể thực hiện được.
Giá trị thập phân và phân số được hỗ trợ:
>>> từ nhập thập phân Thập phân dưới dạng D >>> phương sai([D("27.5"), D("30.25"), D("30.25"), D("34.5"), D("41.75")]) Thập phân('31.01875') >>> từ phân số nhập Phân số dưới dạng F >>> phương sai([F(1, 6), F(1, 2), F(5, 3)]) Phân số(67, 108)
Ghi chú
Đây là phương sai mẫu s² với hiệu chỉnh Bessel, còn được gọi là phương sai có N-1 bậc tự do. Với điều kiện là các điểm dữ liệu mang tính đại diện (ví dụ: độc lập và được phân phối giống hệt nhau), kết quả phải là ước tính không thiên vị về phương sai tổng thể thực sự.
Nếu bằng cách nào đó bạn biết được trung bình tổng thể thực tế μ thì bạn nên chuyển nó cho hàm
pvariance()dưới dạng tham số mu để có được phương sai của mẫu.
- statistics.quantiles(data, *, n=4, method='exclusive')¶
Chia data thành các khoảng n liên tục với xác suất bằng nhau. Trả về danh sách các điểm cắt
n - 1ngăn cách các khoảng.Đặt n thành 4 cho các phần tư (mặc định). Đặt n thành 10 cho thập phân. Đặt n thành 100 cho phần trăm, mang lại 99 điểm cắt để tách data thành 100 nhóm có kích thước bằng nhau. Tăng
StatisticsErrornếu n không nhỏ nhất 1.Zz001zz có thể là bất kỳ dữ liệu mẫu nào có thể lặp lại. Để có kết quả có ý nghĩa, số lượng điểm dữ liệu trong data phải lớn hơn n. Tăng
StatisticsErrornếu không có ít nhất một điểm dữ liệu.Các điểm cắt được nội suy tuyến tính từ hai điểm dữ liệu gần nhất. Ví dụ: nếu điểm cắt giảm một phần ba khoảng cách giữa hai giá trị mẫu,
100và112, thì điểm cắt sẽ có giá trị là104.method để tính toán lượng tử có thể thay đổi tùy thuộc vào việc data bao gồm hay loại trừ các giá trị thấp nhất và cao nhất có thể có khỏi tổng thể.
Zz001zz mặc định là "độc quyền" và được sử dụng cho dữ liệu được lấy mẫu từ một tập hợp có thể có nhiều giá trị cực trị hơn giá trị được tìm thấy trong các mẫu. Phần tổng thể nằm dưới i-th của các điểm dữ liệu được sắp xếp m được tính là
i / (m + 1). Cho chín giá trị mẫu, phương pháp sắp xếp chúng và gán các phần trăm sau: 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%.Việc đặt method thành "bao gồm" được sử dụng để mô tả dữ liệu tổng thể hoặc cho các mẫu được biết là bao gồm các giá trị cực trị nhất từ tổng thể. Giá trị tối thiểu trong data được coi là phân vị thứ 0 và giá trị tối đa được coi là phân vị thứ 100. Phần tổng thể nằm dưới i-th của các điểm dữ liệu được sắp xếp m được tính là
(i - 1) / (m - 1). Cho 11 giá trị mẫu, phương pháp sắp xếp chúng và gán các phần trăm sau: 0%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%.Điểm cắt # Decile cho dữ liệu được lấy mẫu theo kinh nghiệm >>> dữ liệu = [105, 129, 87, 86, 111, 111, 89, 81, 108, 92, 110, ... 100, 75, 105, 103, 109, 76, 119, 99, 91, 103, 129, ... 106, 101, 84, 111, 74, 87, 86, 103, 103, 106, 86, ... 111, 75, 87, 102, 121, 111, 88, 89, 101, 106, 95, ... 103, 107, 101, 81, 109, 104] >>> [làm tròn(q, 1) cho q theo phân vị(dữ liệu, n=10)] [81,0, 86,2, 89,0, 99,4, 102,5, 103,6, 106,0, 109,8, 111,0]
Added in version 3.8.
Thay đổi trong phiên bản 3.13: Không còn đưa ra ngoại lệ cho đầu vào chỉ có một điểm dữ liệu duy nhất. Điều này cho phép các ước tính lượng tử được xây dựng tại một điểm mẫu tại một thời điểm dần dần được tinh chỉnh hơn với mỗi điểm dữ liệu mới.
- statistics.covariance(x, y, /)¶
Trả về hiệp phương sai mẫu của hai đầu vào x và y. Hiệp phương sai là thước đo độ biến thiên chung của hai đầu vào.
Cả hai đầu vào phải có cùng độ dài (không ít hơn hai), nếu không thì
StatisticsErrorsẽ tăng lên.Ví dụ:
>>> x = [1, 2, 3, 4, 5, 6, 7, 8, 9] >>> y = [1, 2, 3, 1, 2, 3, 1, 2, 3] >>> hiệp phương sai(x, y) 0,75 >>> z = [9, 8, 7, 6, 5, 4, 3, 2, 1] >>> hiệp phương sai(x, z) -7,5 >>> hiệp phương sai(z, x) -7,5
Added in version 3.10.
- statistics.correlation(x, y, /, *, method='linear')¶
Trả về Pearson's correlation coefficient cho hai đầu vào. Hệ số tương quan Pearson r nhận giá trị từ -1 đến +1. Nó đo lường sức mạnh và hướng của một mối quan hệ tuyến tính.
Nếu method được "xếp hạng", hãy tính Spearman's rank correlation coefficient cho hai đầu vào. Dữ liệu được thay thế bằng cấp bậc. Các mối quan hệ được tính trung bình sao cho các giá trị bằng nhau sẽ nhận được cùng một thứ hạng. Hệ số kết quả đo lường sức mạnh của mối quan hệ đơn điệu.
Hệ số tương quan Spearman phù hợp với dữ liệu thứ tự hoặc dữ liệu liên tục không đáp ứng yêu cầu tỷ lệ tuyến tính đối với hệ số tương quan Pearson.
Cả hai đầu vào phải có cùng độ dài (không ít hơn hai) và không cần phải là hằng số, nếu không thì
StatisticsErrorsẽ tăng lên.Ví dụ với Kepler's laws of planetary motion:
>>> # Mercury, Sao Kim, Trái Đất, Sao Hỏa, Sao Mộc, Sao Thổ, Sao Thiên Vương và Sao Hải Vương >>> chu kỳ quỹ đạo = [88, 225, 365, 687, 4331, 10_756, 30_687, 60_190] # days >>> dist_from_sun = [58, 108, 150, 228, 778, 1_400, 2_900, 4_500] # million km >>> # Show tồn tại một mối quan hệ đơn điệu hoàn hảo >>> tương quan(orbital_ Period, dist_from_sun, Method='ranked') 1.0 >>> # Observe rằng mối quan hệ tuyến tính là không hoàn hảo >>> vòng(tương quan(orbital_ Period, dist_from_sun), 4) 0,9882 >>> # Demonstrate Định luật thứ ba của Kepler: Có mối tương quan tuyến tính >>> # between bình phương chu kỳ quỹ đạo và lập phương của >>> # distance từ mặt trời. >>> Period_squared = [p * p cho p trong quỹ đạo_thời gian] >>> dist_cubed = [d * d * d cho d trong dist_from_sun] >>> round(tương quan( Period_squared, dist_cubed), 4) 1.0
Added in version 3.10.
Thay đổi trong phiên bản 3.12: Đã thêm hỗ trợ cho hệ số tương quan xếp hạng của Spearman.
- statistics.linear_regression(x, y, /, *, proportional=False)¶
Trả về độ dốc và giao điểm của các tham số simple linear regression được ước tính bằng cách sử dụng bình phương tối thiểu thông thường. Hồi quy tuyến tính đơn giản mô tả mối quan hệ giữa biến độc lập x và biến phụ thuộc y theo hàm tuyến tính này:
y = slope * x + chặn + tiếng ồn
trong đó
slopevàinterceptlà các tham số hồi quy được ước tính vànoisebiểu thị độ biến thiên của dữ liệu không được giải thích bằng hồi quy tuyến tính (nó bằng chênh lệch giữa giá trị dự đoán và giá trị thực tế của biến phụ thuộc).Cả hai đầu vào phải có cùng độ dài (không ít hơn hai) và biến độc lập x không thể không đổi; nếu không thì
StatisticsErrorsẽ được nâng lên.Ví dụ: chúng ta có thể sử dụng release dates of the Monty Python films để dự đoán số lượng phim Monty Python tích lũy sẽ được sản xuất tính đến năm 2019 với giả định rằng chúng đã theo kịp tốc độ.
>>> năm = [1971, 1975, 1979, 1982, 1983] >>> phim_total = [1, 2, 3, 4, 5] >>> độ dốc, điểm chặn = tuyến tính_regression(năm, phim_total) >>> vòng(độ dốc * 2019 + giao điểm) 16
Nếu proportional đúng thì biến độc lập x và biến phụ thuộc y được coi là tỷ lệ thuận. Dữ liệu phù hợp với một dòng đi qua điểm gốc. Vì intercept sẽ luôn bằng 0,0 nên hàm tuyến tính cơ bản sẽ đơn giản hóa thành:
y = slope * x + tiếng ồn
Tiếp tục ví dụ từ
correlation(), chúng ta xem xét xem một mô hình dựa trên các hành tinh lớn có thể dự đoán khoảng cách quỹ đạo của các hành tinh lùn tốt đến mức nào:>>> mô hình = hồi quy tuyến tính(thời_bình phương, dist_cubed, tỉ lệ=True) >>> độ dốc = mô hình.độ dốc >>> Các hành tinh # Dwarf: Pluto, Eris, Makemake, Haumea, Ceres >>> chu kỳ quỹ đạo = [90_560, 204_199, 111_845, 103_410, 1_680] # days >>> dự đoán_dist = [math.cbrt(độ dốc * (p * p)) cho p trong quỹ đạo_thời gian] >>> danh sách (bản đồ (vòng, dự đoán_dist)) [5912, 10166, 6806, 6459, 414] >>> [5_906, 10_152, 6_796, 6_450, 414] khoảng cách # actual tính bằng triệu km [5906, 10152, 6796, 6450, 414]
Added in version 3.10.
Thay đổi trong phiên bản 3.11: Đã thêm hỗ trợ cho proportional.
Ngoại lệ¶
Một ngoại lệ duy nhất được xác định:
- exception statistics.StatisticsError¶
Lớp con của
ValueErrordành cho các trường hợp ngoại lệ liên quan đến thống kê.
đối tượng NormalDist¶
NormalDist là một công cụ để tạo và thao tác các phân phối chuẩn của random variable. Nó là một lớp xử lý giá trị trung bình và độ lệch chuẩn của các phép đo dữ liệu dưới dạng một thực thể duy nhất.
Phân phối chuẩn phát sinh từ Central Limit Theorem và có nhiều ứng dụng trong thống kê.
- class statistics.NormalDist(mu=0.0, sigma=1.0)¶
Trả về một đối tượng NormalDist mới trong đó mu đại diện cho arithmetic mean và sigma đại diện cho standard deviation.
Nếu sigma âm, tăng
StatisticsError.- mean¶
Thuộc tính chỉ đọc cho arithmetic mean của phân phối chuẩn.
- stdev¶
Thuộc tính chỉ đọc cho standard deviation của phân phối chuẩn.
- classmethod from_samples(data)¶
Tạo một phiên bản phân phối chuẩn với các tham số mu và sigma được ước tính từ data bằng cách sử dụng
fmean()vàstdev().Zz003zz có thể là bất kỳ iterable nào và phải bao gồm các giá trị có thể được chuyển đổi thành loại
float. Nếu data không chứa ít nhất hai phần tử, hãy tăngStatisticsErrorvì cần ít nhất một điểm để ước tính giá trị trung tâm và ít nhất hai điểm để ước tính độ phân tán.
- samples(n, *, seed=None)¶
Tạo các mẫu ngẫu nhiên n cho giá trị trung bình và độ lệch chuẩn nhất định. Trả về một giá trị
listcủafloat.Nếu seed được cung cấp, hãy tạo một phiên bản mới của trình tạo số ngẫu nhiên cơ bản. Điều này rất hữu ích để tạo ra các kết quả có thể lặp lại, ngay cả trong bối cảnh đa luồng.
Thay đổi trong phiên bản 3.13.
Chuyển sang thuật toán nhanh hơn. Để sao chép mẫu từ các phiên bản trước, hãy sử dụng
random.seed()vàrandom.gauss().
- pdf(x)¶
Sử dụng probability density function (pdf), tính khả năng tương đối rằng một biến ngẫu nhiên X sẽ ở gần giá trị x đã cho. Về mặt toán học, đó là giới hạn của tỷ số
P(x <= X < x+dx) / dxkhi dx tiến tới 0.Khả năng tương đối được tính bằng xác suất của một mẫu xuất hiện trong phạm vi hẹp chia cho chiều rộng của phạm vi (do đó có từ "mật độ"). Vì khả năng xảy ra có liên quan đến các điểm khác nên giá trị của nó có thể lớn hơn
1.0.
- cdf(x)¶
Sử dụng cumulative distribution function (cdf), tính xác suất để biến ngẫu nhiên X nhỏ hơn hoặc bằng x. Về mặt toán học, nó được viết là
P(X <= x).
- inv_cdf(p)¶
Tính hàm phân phối tích lũy nghịch đảo, còn được gọi là hàm quantile function hoặc percent-point. Về mặt toán học, nó được viết là
x : P(X <= x) = p.Tìm giá trị x của biến ngẫu nhiên X sao cho xác suất của biến đó nhỏ hơn hoặc bằng giá trị đó bằng xác suất đã cho p.
- overlap(other)¶
Đo lường sự phù hợp giữa hai phân bố xác suất chuẩn. Trả về giá trị từ 0,0 đến 1,0 cho the overlapping area for the two probability density functions.
- quantiles(n=4)¶
Chia phân phối chuẩn thành các khoảng liên tục n với xác suất bằng nhau. Trả về danh sách (n - 1) điểm cắt ngăn cách các khoảng.
Đặt n thành 4 cho các phần tư (mặc định). Đặt n thành 10 cho số thập phân. Đặt n thành 100 cho phần trăm, cung cấp 99 điểm cắt để tách phân phối chuẩn thành 100 nhóm có kích thước bằng nhau.
- zscore(x)¶
Tính Standard Score mô tả x theo số độ lệch chuẩn trên hoặc dưới giá trị trung bình của phân phối chuẩn:
(x - mean) / stdev.Added in version 3.9.
Các phiên bản của
NormalDisthỗ trợ cộng, trừ, nhân và chia cho một hằng số. Các hoạt động này được sử dụng để dịch và chia tỷ lệ. Ví dụ:>>> nhiệt độ_tháng 2 = NormalDist(5, 2.5) # Celsius >>> nhiệt độ_tháng 2 * (5/9) + 32 # Fahrenheit NormalDist(mu=41.0, sigma=4.5)
Việc chia hằng số cho một phiên bản
NormalDistkhông được hỗ trợ vì kết quả sẽ không được phân phối bình thường.Vì phân phối chuẩn phát sinh từ tác động cộng gộp của các biến độc lập nên có thể biểu diễn add and subtract two independent normally distributed random variables dưới dạng các thể hiện của
NormalDist. Ví dụ:>>> Birth_weights = NormalDist.from_samples([2.5, 3.1, 2.1, 2.4, 2.7, 3.5]) >>> drug_effect = NormalDist(0.4, 0.15) >>> kết hợp = cân nặng khi sinh + tác dụng của thuốc >>> vòng(combined.mean, 1) 3.1 >>> vòng(combined.stdev, 1) 0,5
Added in version 3.8.
Ví dụ và Bí quyết¶
Các bài toán xác suất cổ điển¶
NormalDist dễ dàng giải được các bài toán xác suất cổ điển.
Ví dụ: cho historical data for SAT exams cho thấy điểm số thường được phân phối với giá trị trung bình là 1060 và độ lệch chuẩn là 195, hãy xác định phần trăm học sinh có điểm kiểm tra từ 1100 đến 1200, sau khi làm tròn đến số nguyên gần nhất:
>>> sat = NormalDist(1060, 195)
>>> phân số = sat.cdf(1200 + 0,5) - sat.cdf(1100 - 0,5)
>>> vòng(phân số * 100.0, 1)
18,4
Tìm quartiles và deciles cho điểm SAT:
>>> list(map(round, sat.quantiles()))
[928, 1060, 1192]
>>> list(map(round, sat.quantiles(n=10)))
[810, 896, 958, 1011, 1060, 1109, 1162, 1224, 1310]
Đầu vào Monte Carlo cho mô phỏng¶
Để ước tính mức phân bổ cho một mô hình không dễ giải quyết bằng phương pháp phân tích, NormalDist có thể tạo các mẫu đầu vào cho Monte Carlo simulation:
>>> mô hình def(x, y, z):
... trả về (3*x + 7*x*y - 5*y) / (11 * z)
...
>>> n = 100_000
>>> X = NormalDist(10, 2.5).samples(n,seed=3652260728)
>>> Y = NormalDist(15, 1.75).samples(n,seed=4582495471)
>>> Z = NormalDist(50, 1.25).samples(n,seed=6582483453)
>>> quantiles(map(model, X, Y, Z))
[1.4591308524824727, 1.8035946855390597, 2.175091447274739]
Xấp xỉ phân phối nhị thức¶
Phân phối chuẩn có thể được sử dụng để ước tính Binomial distributions khi kích thước mẫu lớn và khi xác suất thử nghiệm thành công là gần 50%.
Ví dụ: một hội nghị nguồn mở có 750 người tham dự và hai phòng có sức chứa 500 người. Có một cuộc nói chuyện về Python và một cuộc nói chuyện khác về Ruby. Trong các hội nghị trước đây, 65% người tham dự thích nghe các bài nói chuyện về Python hơn. Giả sử sở thích của mọi người không thay đổi, xác suất phòng Python sẽ nằm trong giới hạn sức chứa của nó là bao nhiêu?
>>> n = 750 kích thước # Sample
>>> p = 0,65 # Preference cho Python
>>> q = 1.0 - p # Preference cho Ruby
>>> k = 500 dung lượng # Room
>>> # Approximation sử dụng phân phối chuẩn tích lũy
>>> từ sqrt nhập toán
>>> round(NormalDist(mu=n*p, sigma=sqrt(n*p*q)).cdf(k + 0.5), 4)
0,8402
>>> Giải pháp # Exact sử dụng phân phối nhị thức tích lũy
>>> từ lược nhập toán, fsum
>>> round(fsum(comb(n, r) * p**r * q**(n-r) cho r trong phạm vi(k+1)), 4)
0,8402
>>> # Approximation sử dụng mô phỏng
>>> từ hạt giống nhập khẩu ngẫu nhiên, nhị thức
>>> hạt giống(8675309)
>>> trung bình(binomialvariate(n, p) <= k for i in range(10_000))
0,8406
Trình phân loại Bayesian ngây thơ¶
Phân phối chuẩn thường phát sinh trong các vấn đề học máy.
Wikipedia có nice example of a Naive Bayesian Classifier. Thách thức là dự đoán giới tính của một người từ các phép đo các đặc điểm được phân phối chuẩn bao gồm chiều cao, cân nặng và kích thước bàn chân.
Chúng tôi được cung cấp một tập dữ liệu huấn luyện có số đo cho tám người. Các phép đo được giả định là có phân phối chuẩn, vì vậy chúng tôi tóm tắt dữ liệu bằng NormalDist:
>>> Height_male = NormalDist.from_samples([6, 5.92, 5.58, 5.92])
>>> Height_female = NormalDist.from_samples([5, 5.5, 5.42, 5.75])
>>>weight_male = NormalDist.from_samples([180, 190, 170, 165])
>>>weight_female = NormalDist.from_samples([100, 150, 130, 150])
>>> foot_size_male = NormalDist.from_samples([12, 11, 12, 10])
>>> foot_size_female = NormalDist.from_samples([6, 8, 7, 9])
Tiếp theo, chúng tôi gặp một người mới có số đo đặc điểm đã được biết nhưng không xác định được giới tính:
>>> ht = 6.0 # height
>>> wt = 130 # weight
>>> kích thước fs = 8 # foot
Bắt đầu với 50% prior probability là nam hoặc nữ, chúng tôi tính số sau là tích của các khả năng xảy ra đối với các phép đo đặc điểm cho giới tính:
>>> trước_male = 0,5
>>> trước_nữ = 0,5
>>> posterior_male = (prior_male * Height_male.pdf(ht) *
... trọng lượng_male.pdf(wt) * foot_size_male.pdf(fs))
>>> posterior_female = (prior_female * Height_female.pdf(ht) *
... trọng lượng_female.pdf(wt) * foot_size_female.pdf(fs))
Dự đoán cuối cùng đi đến phần sau lớn nhất. Điều này được gọi là maximum a posteriori hoặc MAP:
>>> 'nam' nếu postior_male > posterior_female nếu không là 'nữ'
'nữ'